

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- SQL
- GCP
- Til
- django
- superset
- 코딩 테스트
- airflow
- 코테 연습
- VPC
- 코딩테스트
- AWS
- Selenium
- Kafka
- 데이터 엔지니어
- 팀 프로젝트
- Tableau
- HTML
- 데이터 시각화
- cloud platform
- 데브코스
- Snowflake
- beuatifulsoup
- PCCP
- Spark
- 슈퍼셋
- Today
- Total
주니어 데이터 엔지니어 우솨's 개발일지
데이터 엔지니어링 55일차 TIL 본문
학습 내용
dbt seed란?
- 많은 dimension 테이블들을 csv파일 형태로 쉽게 만든 후 데이터웨어하우스에 테이블로 로딩해주는 기능
1. seeds 폴더에 csv파일 저장
2. dbt run
=> csv파일을 redshift에 바로 저장
- 다른 SQL에서 사용시 Jinjatamplate 사용
: {{ ref("reference_date") }}
Staging 테이블을 만들 때 입력 테이블이 자주 바뀐다면?
- models 밑의 .sql 파일들을 일일이 찾아 바꿔주어야한다.
- 번거롭고 실수가 나오기 쉽다.
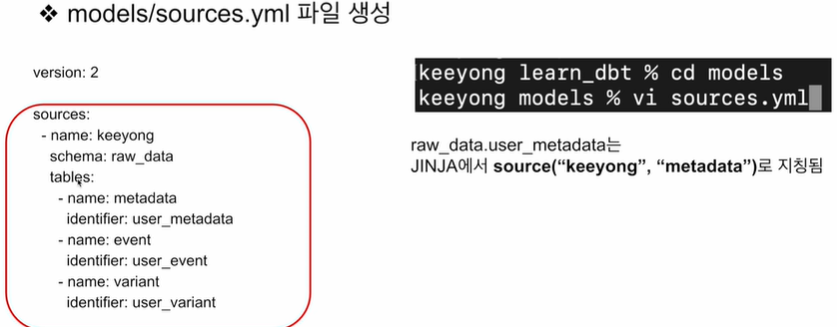
- 이 번거로움을 해결하기 위한 것이 Sources
- 입력 테이블에 별칭을 주고 별칭을 staging 테이블에서 사용한다.
DBT Sources 란?
- 외부 데이터 소스를 참조하여 원본 데이터를 변형하거나 모델링할 때 사용하는 구조체로, dbt 프로젝트 내에서 원본 데이터의 메타데이터를 관리하고 추적할 수 있게 한다.
- 기본적으로 처음 입력이 되는 ETL테이블들을 대상으로 한다.
- raw.data 테이블에 별칭(alias)을 부여한 뒤 변경처리를 용이하게 한다.
- source 이름과 새 테이블의 이름의 두가지로 구성된다.

Sources 최신성(Freshness)
- 특정 데이터가 소스와 비교해서 얼마나 최신성이 떨어지는지 체크하는 기능
- dbt source freshness 명령으로 수행
- 이를 하려면 models/sources.yml의 해당 테이블 밑에 아래 추가

데이터베이스에서의 스냅샷(Snap Shot)이란?
- dbt에서는 테이블의 변화를 계속적으로 기록함으로써 과거 어느 시점이건 다시 돌아가서 테이블의 내용을 볼 수 있는 기능이다.
- 테이블에 문제가 있을 경우 과거 데이터로 롤백이 가능하다.
- 다양한 데이터 관련 문제 디버깅도 쉬워진다.
dbt의 스냅샷 처리 방법
- snapshots 폴더에 환경설정이 된다.
- snapshots을 위한 조건이 만족해야한다.
- Primary key가 존재해야한다.
- 레코드의 변경식나을 나타내는 타임스탬프가 필요하다(ex. updated_at, modified_at 등)
- 변경 감지 기준
- Primary key 기준으로 변경시간이 현재 DW에 있는 시간보다 미래인 경우
- Snapshots 테이블에는 총 4개의 타임스탬프가 존재한다.
- dbt_scd_id, dbt_updated_at
- valid_from, valid_to

DBT에서의 Test
- 데이터 품질을 테스트하는 방법
- 내장 일반 테스트(Generic) --models 폴더 : unique, not_null,accepted_values,relationships 등의 테스트를 지원
- 커스텀 테스트(Singular) --test 폴더: 기본적으로 SELECT로 간단하며 결과가 리턴되면 "실패"로 간주한다.


DBT 문서화
- 문서와 소스 코드를 최대한 가깝게 배치하는 것
- 기존 .yml 파일에 문서화 추가(선호)
- 독립적인 markdown 파일 생성
- 이를 경량 웹서버로 서빙한다.
- overiew.md가 기본 홈페이지가 된다.(이미지 등의 asset 추가도 가능하다)

DBT Expectations
- Great Expectations에서 영감을 받아 dbt용으로 만든 dbt 확장판
- https://github.com/calogica/dbt-expectations
- 설치 후 packages.yml에 등록
packages:
- package: calogica/dbt_expectations
version: [">=0.7.0", "<0.8.0"]
dbt Expectations 함수들
- expect_column_to_exist
- expect_row_values_to_have_recent_data
- expect_column_values_to_be_null
- expect_column_values_to_not_be_null
- expect_column_values_to_be_unique
- expect_column_values_to_be_of_type
- expect_column_values_to_be_in_set
- expect_column_values_to_not_be_in_set
- expect_column_values_to_be_between
데이터 카탈로그
- 데이터 자산 메타 정보 중앙 저장소
- 데이터 거버넌스의 첫 걸음
- 많은 회사에서 데이터 카탈로그를 데이터 거버넌스 툴로 사용하거나 데이터 카탈로그 위에 커스텀 기능을 구현한다.
- 주요기능
- (반) 자동화된 메타 데이터 수집
- 데이터 보안! -- 보통 메타데이터만 읽어온다.
DBT에서의 ELT

DBT는 Template화된 SQL
- DBT 코드 = SQL + Jinja template
- 모델부터 작성하는데 이는 하나의 SELECT문이라고 볼 수 있다.
- A model == A SELECT statement
- 다양한 검증 방법이 추가 가능하다.
- Generic tests, One-off test
- 테이블의 스냅샷 추가 기능
데이터 카탈로그 툴
- 상용제품
- 정통적 : Alation, Collibra
- 스타트업 : Atlan, Select Star, Great Expectations
- 오픈소스
- Amundsen, DataHub
- 클라우드 서비스
- AWS Glue Data Catalog
- Google Cloud Data Catalog
- Microsoft Azure Data Catalog (Purview Data Catalog로 통합중)
- 자체 툴
- DataBook(Uber)
- Dataportal(Airbnb)
'데브코스' 카테고리의 다른 글
| 데이터 엔지니어링 57일차 TIL (0) | 2024.06.30 |
|---|---|
| 데이터 엔지니어링 56일차 TIL (0) | 2024.06.17 |
| 데이터 엔지니어링 54일차 TIL (0) | 2024.06.06 |
| 데이터 엔지니어링 53일차 TIL (1) | 2024.06.05 |
| 데이터 엔지니어링 52일차 TIL (1) | 2024.06.05 |


